Transitioning to virtual threads using the Micronaut loom carrier
by Jonas KonradMicronaut HTTP Server Netty 4.9 introduces a new, experimental “loom carrier mode” for the Netty event loop. This prototype uses internal JDK APIs to run virtual threads directly on the event loop, under control of the framework. Our goal is to provide performance characteristics comparable to reactive code, with the convenience and “safety net” that virtual threads provide.
The Netty threading model
Netty is a general-purpose framework for networking applications. Years of development have gone into some of the fastest protocol implementations available for the JVM. The use of native libraries to replace JDK APIs, such as the io_uring-based transport or the OpenSSL-based TLS implementation, push performance further. This has made it the natural choice for the basis of “next generation” web servers, such as Micronaut HTTP, Quarkus (Vert.x), and Spring WebFlux (reactor-netty).
From the ground up, Netty is designed with an asynchronous programming model. Whereas traditional networking frameworks spin up a thread for each connection and use blocking operations to read from or write to the connection, Netty uses only a few threads, so-called event loops, that can each serve many connections.
The most well-known advantage of this programming model is straight-forward: You need fewer threads. Platform threads (as opposed to the new virtual threads) require a fairly large amount of memory for the stack, causing problems when dealing with thousands of connections. Each new connection requires starting up a new thread, which can be expensive. Switching between processing different connections requires an OS-level context switch.
But the benefits don’t stop there. New APIs and protocols are designed with this programming model in mind. For example, HTTP/2 bundles many requests on the same connection. Processing these streams in a synchronous fashion would need a thread for each request, and logic to distribute data to these threads. Similarly, Linux’ new io_uring API, which offers superior IO performance by saving on syscalls, is modeled for a single user mode platform thread consuming the data of many asynchronous IO operations.
Finally, there are gains to be had from sharing resources among connections but not among event loops. A pool of IO buffers does not need complicated (and slow!) synchronization operations to function if it is restricted to an event loop where all multitasking is cooperative and no other threads can interfere.
The big downside to asynchronous programming is the added complexity, however. Code on the event loop must not block: Doing so will not only stall progress for the current connection, but potentially many others as well. In Netty, decoders must always verify that enough input data is available before decoding, and save their progress to fields when there isn’t. In higher-level frameworks built on Netty, network operations often use callbacks or reactive streams that will complete asynchronously with the operation. The difficulty of debugging such code is notorious. Wouldn’t it be nice to write “normal” blocking code, but still get the benefits of asynchronous code? Enter virtual threads.
Virtual Threads
Many approaches have been tried to make asynchronous programming easier in various languages. The JDK team has chosen an ambitious one: Virtual threads that behave almost identically to platform threads. As opposed to async-await or Kotlin’s suspended functions, this requires no change to (most) existing blocking code to work. This is a great benefit to the large existing ecosystem that still uses blocking operations, but it’s also convenient for “rarely blocking” code. For example, a log statement is usually thrown around without a callback waiting for its completion, but may block in rare situations. You still want to avoid blocking the event loop then.
Virtual threads are less memory intensive than platform threads, they are relatively cheap to start, and when a virtual thread goes idle, the carrier thread can pick up another without a heavy context switch. We can start a virtual thread for every connection or every HTTP/2 request with no issue.
Virtual threads work using continuations. Blocking operations in the standard library, such as Thread.sleep, have a special path for virtual threads. Instead of actually performing a sleep system call, the JDK instead tells the JVM to yieldthe virtual thread. The JVM saves thread information (e.g. the stack) to a heap data structure. Once the sleep finishes, the JDK will tell the JVM to restore the stack and can continue execution of the virtual thread.
The separation of responsibilities to make this happen in the JDK is quite neat. The suspension and resumption logic is distinct from the scheduler. A virtual thread is encapsulated by a Runnable that is submitted to an Executor. When the virtual thread needs to suspend, Runnable.run() finishes. When the thread is resumed, the thread is resubmitted using Executor.execute(Runnable). The Executor implementation is implemented purely in Java.
The Executor used for virtual threads in the JDK is a dedicated ForkJoinPool. This pool compromises between localityand progress: Each platform thread has a local queue and the submission logic tries to avoid moving tasks between platform threads unnecessarily, but if a task “hogs” a platform thread e.g. for a long CPU-intensive operation, other platform threads can steal queued tasks to make sure they progress anyway. This approach works reasonably well, but when combined with Netty, there are some drawbacks.
Netty and the ForkJoinPool (FJP) don’t mix well
Say we have a Netty-based web server and want to run each request on a virtual thread for user convenience. The first dilemma is where to run the event loop. If we run the event loop as a virtual thread on the FJP, request tasks can run on the same carrier thread without a context switch. There are three reasons why this doesn’t work, however.
- In Netty, the most performant transport implementations use native code. In this native code, Netty sends off system calls that may block the current thread until data becomes available. The JVM cannot suspend the virtual thread in this case–the carrier thread is stuck even though it’s not busy and could be running continuations.
- The second issue is that the FJP may transfer the event loop to another platform thread between different iterations. This is forbidden e.g. by io_uring. If we want to use io_uring, we must ensure that the event loop remains on the same platform thread throughout its lifetime. That leaves us only the option to run the event loop outside the FJP, which means we have to live with the cost of context switching between the FJP and the event loop for every request and response.
- Another problem with FJP is that while it tries to keep virtual threads local, framework-level knowledge is missing. We’ve seen benchmarks where several HTTP/2 requests that come in on one connection would end up being distributed all over the FJP, leading to large synchronization overhead when the responses have to be merged back into a single TCP connection. In the other direction, when using a DB connection pool, we can gain some performance by picking DB connections that run on the same event loop as the server connection. A shoutout to Vert.x in particular for making this easy–and benefiting from it in benchmarks.
A framework-level solution
I’ve described above the abstraction the JDK uses internally to run virtual threads. The FJP is simply used as an Executor. What if we were to replace this Executor with something we have more control over? The necessary APIs are private–we need the --add-opens=java.base/java.lang=ALL-UNNAMED JVM argument, and a healthy dose of reflection–but the infrastructure exists. With the loom carrier prototype, we make that option available for you to try.
For every event loop, there is a carrier thread. The event loop itself runs on a virtual thread on that carrier thread, but is treated specially. The event loop will only enter the native blocking code if the carrier thread really is idle and there are no other virtual threads to run. On the other side, when a virtual thread is submitted to the carrier while the event loop is sleeping in native code, we wake the event loop and return control to the carrier so that we can run the submitted work. This way, we resolve the event loop on FJP issues listed above.
When a request comes in, a virtual thread is created on the same carrier thread, so we don’t need to context switch. We can even go a step further with immediate run: Inside an event loop read event handler, we can submit the request processing task, yield the event loop thread, run the request handler virtual thread, and then return to the event loop. The response is available before the event loop even finishes with its read handler. When this works out, the performance advantage can be significant, in particular when the same read event contains multiple requests that can have their responses batched–something we could only achieve with async code before. When it doesn’t work out and the controller has to block, we don’t get this benefit, but the event loop doesn’t come crashing to a halt either. The best of both worlds.
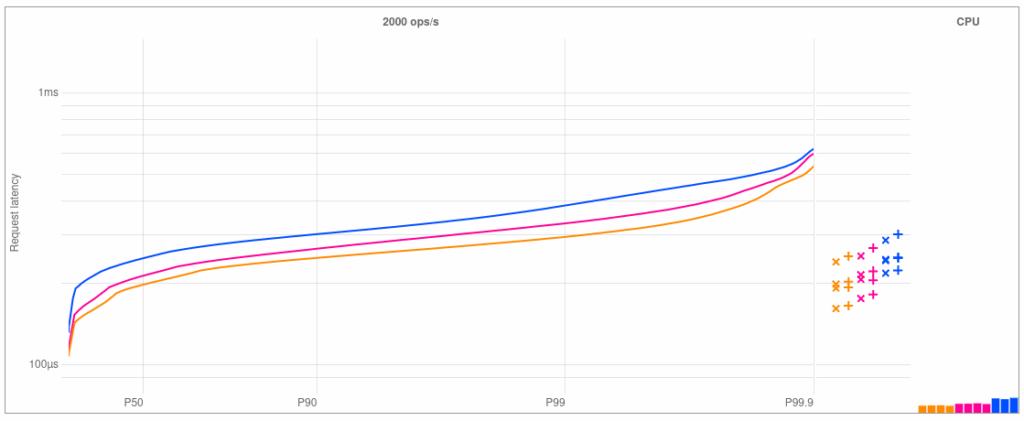
This is a great start! Now let’s look beyond the “immediate response” use case.
Client affinity
I briefly touched on an optimization event loops can do above that I call client affinity. A Netty event loop can handle multiple connections at a time, but this is not limited to server connections. It’s possible to run HTTP client or database connections on the same event loop as the server. This avoids context switching between the IO thread of the request we’re serving and the IO thread of the client connection we’re using to fetch data.
The difficulty with this optimization is that it necessarily requires specialized logic in the connection pool. Migrating a connection to a new thread is difficult to impossible, so when a controller requests a connection from the pool, the pool must be programmed to only choose among the connections on the same event loop as that controller.
The Micronaut HTTP client has had this feature since 4.8, and further improved in 4.9, but only async code could benefit from affinity before. When the controller runs on a virtual thread on the FJP, there is little point in the client sharing the event loop with the server, because the response returned by the client will have to pass through the virtual thread on the FJP before making it back to the event loop anyway. With the event loop carrier however, this optimization finally becomes feasible with virtual threads.
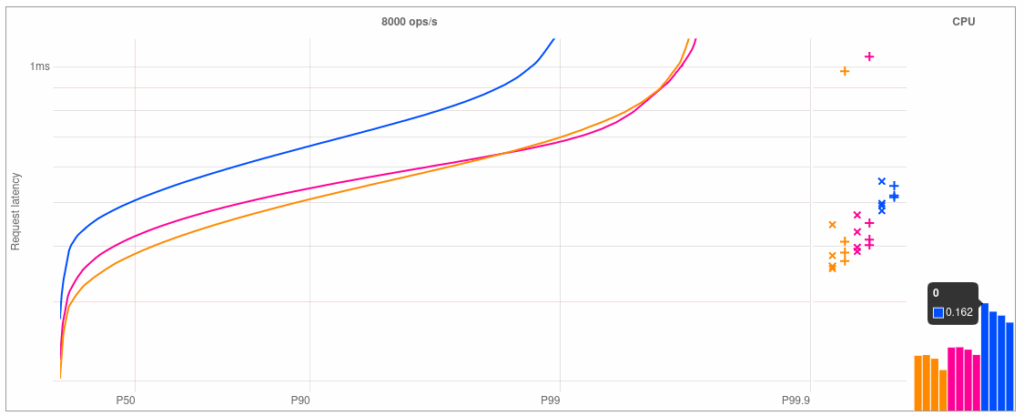
From the results, we can see that the optimization works and latency ends up very close to the async implementation (which also uses client affinity). This approach is transparent to the user.
Non-Netty IO
While Netty-based IO works great, most external code uses normal JDK IO operations. With virtual threads, blocking IO is implemented using two levels of pollers.
- When
InputStream.read()is called, first a non-blocking read is attempted. - If data isn’t available immediately, the file descriptor is registered with a sub poller (chosen by the numeric FD value). The sub pollers are themselves virtual threads. When they see data become available, they wake up the virtual thread that’s waiting for it. Due to how virtual threads and the FJP work, this wakeup will usually need no context switch, the blocking thread will run on the same carrier thread as the sub poller that woke it up.
- If the sub poller also needs to wait because none of the files registered to it have data available, it registers with the master poller and goes to sleep itself. The master poller is a proper platform thread, not a virtual thread, so waking up the sub poller at that point does lead to a context switch.
This setup is fairly rigid at the moment. There is no way for us to create our own sub pollers for a particular event loop, and even if we could, there would be no way to assign particular file descriptors to the “right” sub poller. In fact, the event loop carrier prototype has to take extra care to make sure that the poller virtual threads stay on the FJP and don’t all start on the event loop by accident.
The best we can do for now is try to make JDK IO no worse than with FJP. When a controller virtual thread on the event loop carrier performs a blocking IO operation (i.e. waits using the sub poller), it is “moved” to the FJP temporarily, so that it can do its IO there. This is one context switch. Once IO is done and the controller thread interacts with the event loop again, it can be moved back, leading to a second context switch. Not ideal, but two context switches is the same cost we’d have paid if the controller virtual thread had run on the FJP from the start.
Measuring this with a realistic example is surprisingly difficult. The Micronaut HTTP client uses Netty, so it doesn’t work as an example. The new JDK HttpClient has its own event loop architecture using a separate platform thread and doesn’t use the pollers either. The test case I settled on instead is a JDBC PostgreSQL connection using the Hikari connection pool. A fairly common setup, though Hikari and the JDBC driver have their own performance issues that interfere with the benchmark a bit.

In the benchmark, the latency and CPU usage are on par with FJP, which is what we want. However, the loom carrier approach cannot handle a request rate as high as the pure FJP approach. This needs further work, but one possible explanation is related to HikariCP: In the loom carrier mode, connection acquisition happens on the event loop carrier thread, while release happens on the FJP. This could lead to more synchronization overhead and context switching when compared against the test where acquisition also happens on the FJP.
Balancing tasks
One area where the event loop carrier approach differs substantially from the FJP is work stealing. FJP will transfer tasks between carrier threads much more freely. In some benchmarks this can become a disadvantage, with e.g. virtual threads of different HTTP/2 streams on the same connection being distributed to other carrier threads with little care, leading to unnecessary context switching and synchronization overhead to coordinate the response writing. But it can also go the other way. If there is a load burst on one event loop and the request processing is fairly heavy, the overhead from distributing tasks is smaller than the advantage gained from parallel processing. In an Oracle-internal synthetic benchmark this lead to a striking initial latency advantage for the FJP. I was able to tune the event loop carrier to reach performance on par with the FJP, but such optimization always runs the risk of “overfitting” a particular benchmark, with little benefit or even performance losses for real world applications.
It is likely that there will always be applications that perform worse when running their virtual threads on the event loop compared to running them on the FJP. Improving locality and reducing migration between CPUs will always come with tradeoffs–but it’s nice to have the option to customize the scheduler to your needs.
Where to go from here
Where we can, in principle, always compete, is async code. There is no fundamental reason why a reactive controller should be faster than the same reactive controller on a virtual thread on the event loop–we don’t pay the fixed FJP and context switch overhead after all. In practice there is still a gap, but there doesn’t have to be. If we can match the performance, we can take the step to making virtual threads the default for our users, without risking performance regressions in existing applications. Applications will get the “safety net” of virtual threads, where accidental blocking operations don’t stall the event loop. Folks that are already committed to blocking code and virtual threads can try the event loop carrier, or could continue using the FJP if that’s where their application performs better.
Then, of course, there’s the JDK API side. This entire effort relies on reflecting into the JDKs innards, and the folks at Red Hat have even gone a step further and experimented with JDK patches. For production use, the JDK would have to open up scheduling APIs. Those APIs can be dangerous to use and restrict the JDK in what changes can be made in the future, so they will have to be designed with care.
We’d love to hear your feedback on this prototype. Test your applications–be they reactive or blocking–with the event loop carrier to see if there are major performance regressions or improvements. To use the event loop carrier, set the following configuration properties:
# run controllers on virtual threads
micronaut.server.thread-selection=blocking
# enable the event loop carrier on the default event loop
micronaut.netty.event-loops.default.loom-carrier=true
# make the HTTP client use the same event loop as the server to take advantage of client affinity
micronaut.http.client.event-loop-group=default
# optional: throw an exception if client affinity does not engage
#micronaut.http.client.pool.connection-locality=enforced-always
If you have feedback on the general design or the JDK APIs, that would also be appreciated. You can contact us in the micronaut-core discussions forum.
Acknowledgements
This work would not have been possible without the help of the Red Hat folks from the Quarkus and OpenJDK teams. They laid the necessary groundwork to make Netty fast on virtual threads and to introduce the Netty APIs necessary for this level of event loop customization. They also provided feedback throughout the development process, and worked closely with us to solve functional and performance problems we encountered.
Appendix A: Deadlocks and running with scissors
Implementing a custom virtual thread scheduler is risky business. One particular problem that we did not encounter in practice but played a big part in our design decisions is the risk of deadlocks. When a lock is used both in a carrier thread and a virtual thread that runs on that carrier, a deadlock can appear. If the virtual thread suspends while holding the lock, and then the carrier thread attempts to acquire the same lock, it will block forever because the virtual thread that releases it can never run–its carrier is blocked. Work stealing can mitigate this to some extent, but in more complex settings even that is not enough.
The only real solution is to avoid locks shared between virtual threads and the carrier. But that is easier said than done: For example, logback appenders regularly use synchronized, so if the carrier thread does any logging at all it risks deadlocking with its virtual threads that certainly will log. Again, we’ve never seen this happen in practice, but the risk is there. When it does happen the event loop will lock up in an unrecoverable state.
For that reason we decided to move the event loop to a virtual thread as described above. Running the event loop directly on the carrier thread carries some performance advantages due to how netty works, but the risk of a deadlock is hard to avoid. With the event loop on a virtual thread, if it does block (hopefully a rare occurrence), it can suspend and other virtual threads can run to unblock it.
Appendix B: Thread local caching
One benefit of event loops over a many-thread architecture that I listed at the start of this article is that we can share resources without expensive synchronization. For example, a buffer pool can be stored in a ThreadLocal and will never have to worry about interference from other threads. You’ll notice that I haven’t talked about this since, and indeed there is still room for improvement here.
The biggest pooling structure Netty uses, its buffer allocator, has been made more efficient for virtual threads with Netty 4.2, thanks to the folks at Red Hat. When ThreadLocal is not feasible, it can instead use the thread ID to select an “arena” that is hopefully uncontended. But even with this approach, some overhead remains. For other pools where the performance gain from pooling is smaller, this overhead is big enough to make pooling simply not worth it anymore.
There is some work to be done here. Something we could do today already is to rely on critical sections, code sections where the carrier thread is fixed, and a virtual thread cannot suspend. Inside this section we can then manipulate a structure local to the carrier thread without worrying about interference.
Because virtual threads are purely cooperative at the moment, we can “emulate” such a section by simply making sure none of the code inside of it may suspend the virtual thread. But this is brittle, and if the JDK ever introduces preemption for virtual threads, it will break. It also relies on internal APIs to access the carrier thread and share data structures.
A better solution would be a JDK API that implements recycling without exposing concepts like critical sections or carrier thread access that may lock the JDK out of future changes to the virtual thread architecture. I’ve written up a proposal here, but it’s in its early stages, and I’m not yet sure that the API can cover all the use cases Netty needs.